问题定义
- 给定一组训练数据{$x^{1}$,$x^{2}$,…,$x^{N}$}
- 找到判断输入数据是否与训练数据相似的一个映射关系
- x与训练集相似,输出正常;否则输出异常
- 不同的目的使用不同的方法来定义相似性
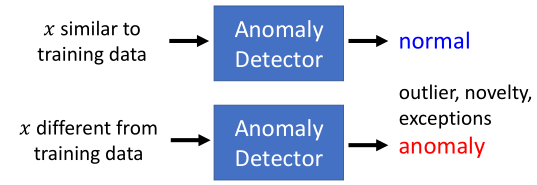
什么是异常?

应用
- 欺诈检测[1][2]
- 网络入侵侦测[3]
- 癌症检测[4]
二值分类
方法:
- 给定正常数据{$x^{1}$,$x^{2}$,…,$x^{N}$}
=>class 1 - 给定异常数据{$\widetilde{x}^1$,$\widetilde{x}^2$,…,$\widetilde{x}^N$}
=>class 2 - 训练一个二值分类器
困难:
- 难以定义异常类,例如:$x$表示宝可梦,但是$\widetilde{x}$可以为任何东西
- 异常的情况难以收集
分类
- 有标记数据
=>使用分类器分类 - 没有标记数据
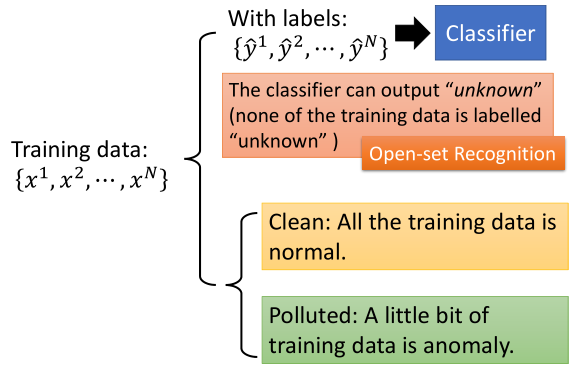
Case 1:使用分类器
1.这里使用辛普森家族数据集[5],首先训练出一个分类器。
2.如何使用分类器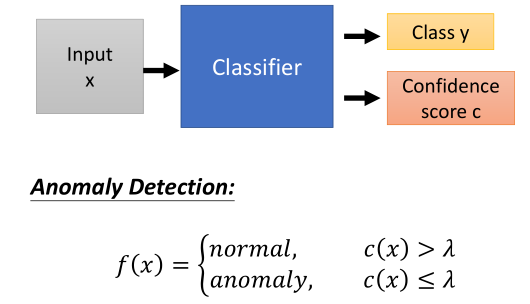
- 输入数据经过分类器,可以得到归属各类的概率(信心分数);
- 如果该值大于阈值$\lambda $,则为正常,否则异常
3.如何评估信心分数
- 最大概率分数
- 负的熵
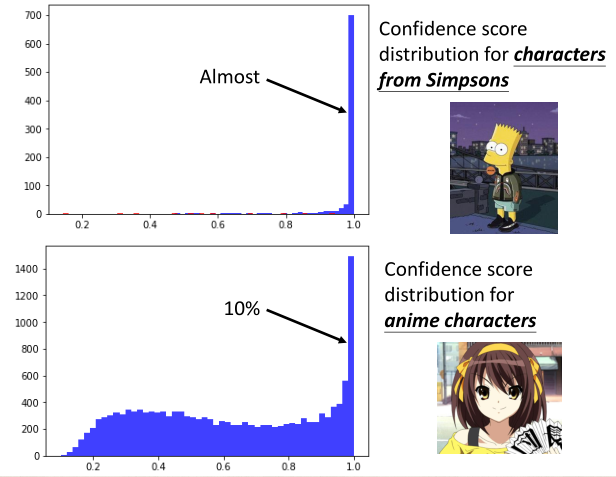
注:属于辛普森家族概率值在1附近,而不属于的输入则概率较小。
4.展望:信心分数评估神经网络
Terrance DeVries, Graham W. Taylor, Learning Confidence for Out-of-Distribution Detection in Neural Networks, arXiv, 2018
5.示例框架
注:
- 训练集中标注数据需要明确所属类别;而验证集中只需要标明是否属于。
- 使用验证集对于训练模型中的$\lambda$超参数进行调节
6.验证
- 精度并不能很好的衡量模型,例如:100正常,5异常,若全判正常
=>$accuracy = 100/(100+5)=95.2\%$ - 正反例使用不同的惩罚分数
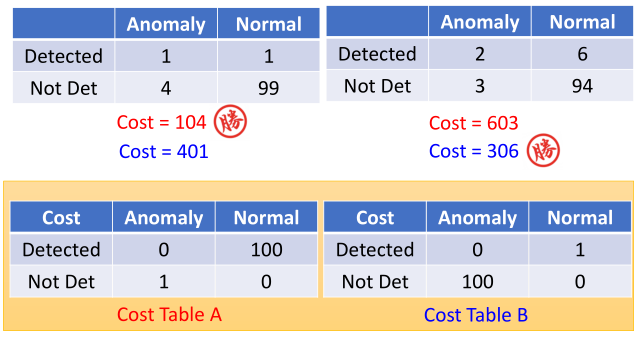
- AUC衡量(AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积)
7.存在的问题
- 猫狗分类器:异常类老虎得分可能比猫更高;异常类狼得分比狗更高
- 分类特征的问题:辛普森家族脸是黄色,如果把人脸图成黄色,则有很高几率判断成正常类。
Case 2:无标记数据
1.问题定义
- 给定一组训练数据{$x^{1}$,$x^{2}$,…,$x^{N}$}
- 我们需要找到一个映射用来判断输入$x$是否类似于训练数据
- twitch-troll-detection实例[6]
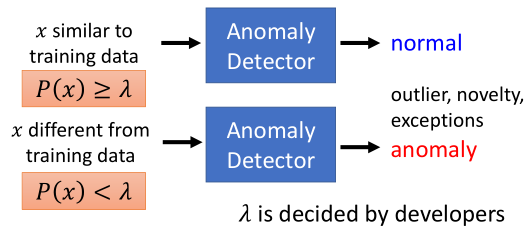
2.极大似然
3.高斯分布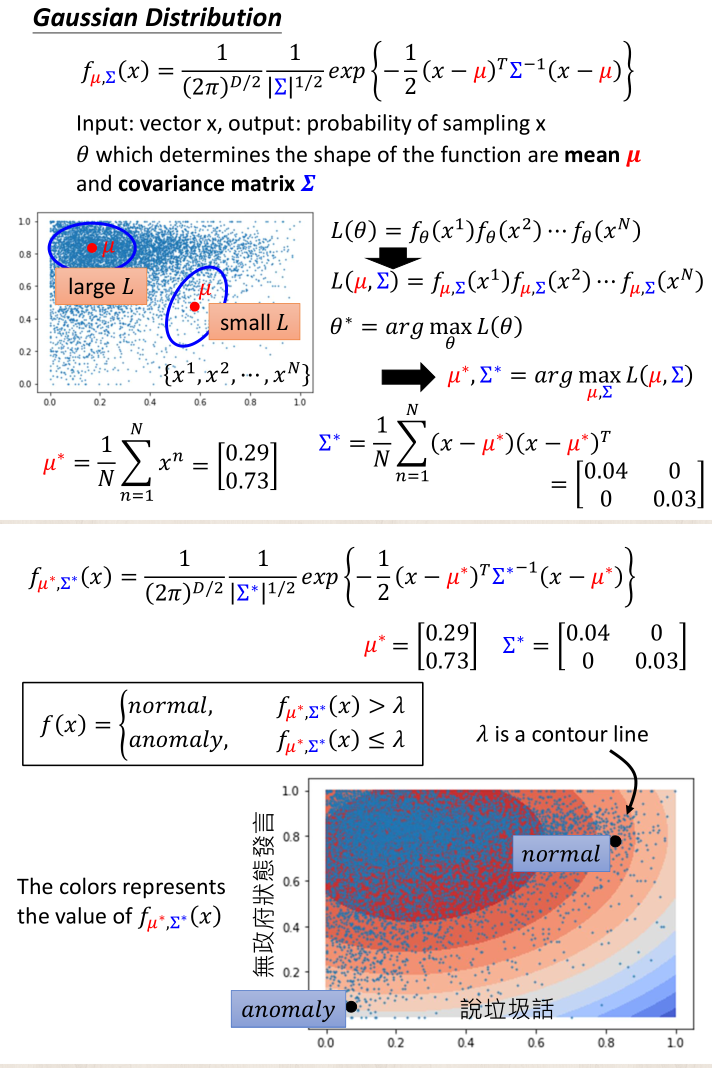
4.展望:auto-encoder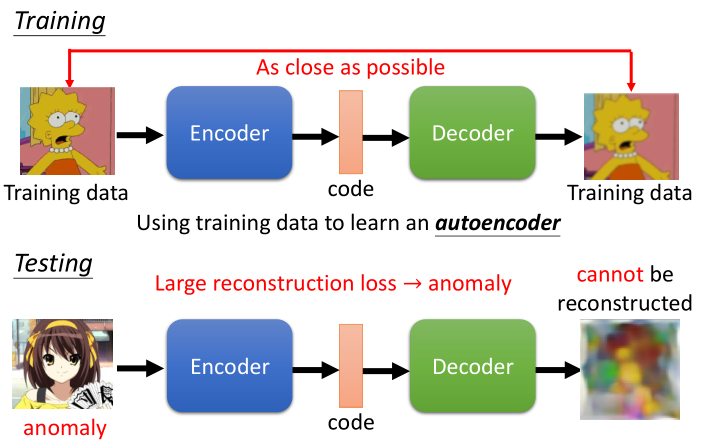
- 正常图片可以使用auto-encoder复原
- 异常图片无法复原
5.更多
- one-class svm
- isolated forest
引用
[1].https://www.kaggle.com/ntnu-testimon/paysim1/home
[2].https://www.kaggle.com/mlg-ulb/creditcardfraud/home
[3].http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html
[4].https://www.kaggle.com/uciml/breast-cancer-wisconsin-data/home
[5].https://www.kaggle.com/alexattia/the-simpsons-characters-dataset/
[6].https://github.com/ahaque/twitch-troll-detection
